Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
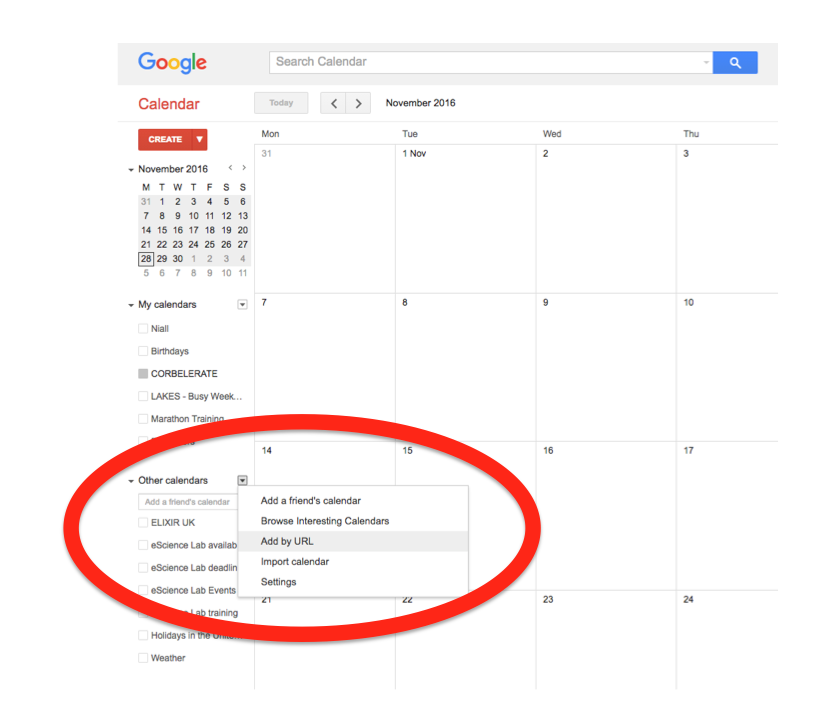
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
Multi-omics comparative pathway analysis with ReactomeGSA

21 October 2020 @ 09:00 - 17:00
Online
Omics Pathway or network Reactome pathways database ReactomeGSA Pathway analysis Single cell RNA-seq Multiomics -
Workshops and courses
EMBL-EBI workshop: University of Pavia, 2021 (Virtual)
1 - 11 February 2021
Online
Genomics Transcriptomics Functional genomics Proteins Protein structure Molecular interactions, pathways and networks Metabolomics Ensembl Expression Atlas ArrayExpress Archive of Functional Genomics Data UniProt: The Universal Protein Resource Protein Data Bank in Europe IntAct Molecular Interaction Database Complex Portal Reactome pathways database Chemical Entities of Biological Interest MetaboLights: Metabolomics repository and reference database DNA & RNA (dna-rna) Gene expression (gene-expression) Proteins (proteins) Structures (structures) Systems (systems) Chemical biology (chemical-biology) -
Workshops and courses
Introduction to multi-omics data integration and visualisation
22 - 26 February 2021
Online
Omics Data architecture, analysis and design Reactome pathways database Omics Discovery Index Multiomics -
Workshops and courses
Introduction to RNA-seq and functional interpretation
16 - 19 March 2021
Online
Expression Atlas ArrayExpress Archive of Functional Genomics Data Reactome pathways database RNAcentral Gene expression (gene-expression) -
Workshops and courses
Proteomics bioinformatics
12 - 16 July 2021
Online
Proteomics PRIDE: The Proteomics Identifications Database IntAct Molecular Interaction Database Reactome pathways database proteomics -
Workshops and courses
CABANA Virtual Workshop: Exploring biological networks and its application in health and disease
8 - 12 November 2021
Online
Reactome pathways database IntAct Molecular Interaction Database Systems (systems) Proteins (proteins) -
Workshops and courses
Bioinformatics resources for protein biology
21 February - 2 March 2022
Online
protein Protein sequence Gene and protein families Protein complex Pathway analysis Protein structure UniProt: The Universal Protein Resource InterPro Pfam HMMER - protein homology search Electron Microscopy Public Image Archive - EMPIAR AlphaFold Database IntAct Molecular Interaction Database Complex Portal Reactome pathways database Proteins (proteins) Protein classification -
Workshops and courses
Bioinformatics resources for protein biology
25 - 27 April 2023
Online
Structure analysis Protein sequence Molecular interactions, pathways and networks UniProt: The Universal Protein Resource Protein Data Bank in Europe Protein Data Bank in Europe - Knowledge Base Electron Microscopy Data Bank IntAct Molecular Interaction Database Reactome pathways database AlphaFold Database InterPro Proteins (proteins) Structures (structures) Systems (systems) protein function electron density map protein structure protein annotation protein sequence classification -
Workshops and courses
Mathematics of life: modelling molecular mechanisms
11 - 15 March 2024
Online
BioModels database Reactome pathways database Network analysis Pathway enrichment Curation -
Workshops and courses
Small molecule chemistry: from proteins to pathways
28 November 2024 @ 09:00 - 17:00
Online
Chemical biology Molecular interactions, pathways and networks Protein structure ChEMBL: Bioactive data for drug discovery PDBeChem Reactome pathways database chemical biology small molecules ligands
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.