Events
Subscribe to Filter
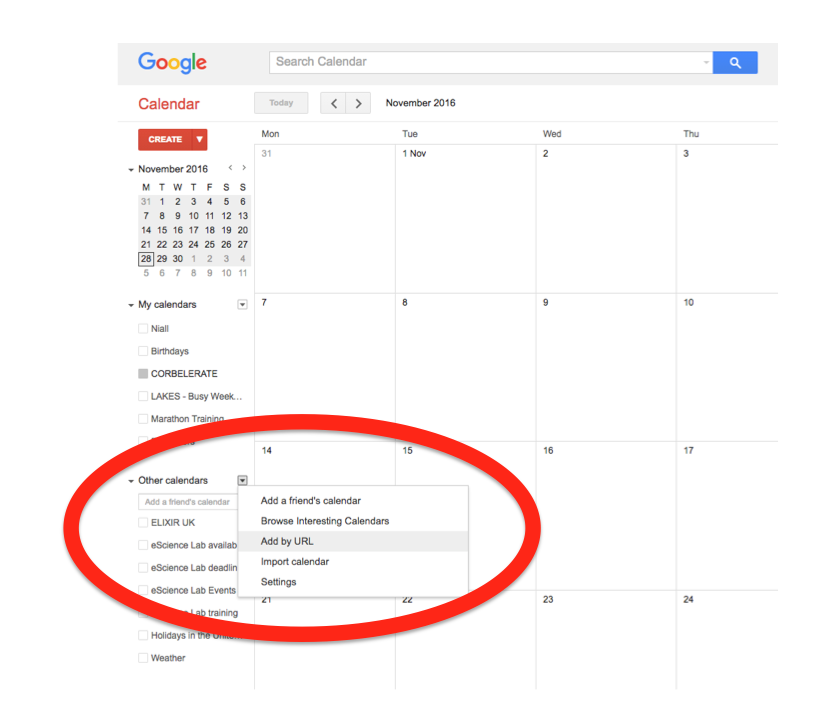
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
Ensembl gene annotation for clinical genomics

18 September 2019 @ 09:00 - 17:00
Online
Genetic linkage report Gene family report RefSeq accession Gene annotation format Ensembl Genes GENCODE Gene annotation Clinical genomics -
Workshops and courses
UNU-BIOLAC and CABANA: Latin American Workshop in Structural Bioinformatics of Proteins
23 - 27 September 2019
Colombia
Face-to-face
Structural biology Structures (structures) Proteins (proteins) -
Workshops and courses
Next generation sequencing bioinformatics
23 - 26 September 2019
United Kingdom
Face-to-face
Sequencing Genomics DNA & RNA (dna-rna) -
Workshops and courses
EMBL-EBI Workshop: Mathematics of life workshop: “Modelling molecular mechanisms: from basic science to drug discovery”
2 October 2019 @ 09:00 - 17:00
United Kingdom
Face-to-face
Mathematical model -
Workshops and courses
Integrating publications into bioinformatics analysis
2 October 2019 @ 09:00 - 17:00
Online
Text annotation Text mining Europe PubMed Central Literature (literature) Europe PMC PubMed -
Workshops and courses
Exploring biological sequences
8 - 10 October 2019
United Kingdom
Face-to-face
Sequence alignment report Sequence analysis Sequence search results -
Workshops and courses
CABANA Train the Trainer Workshop in Lima, Peru
14 - 15 October 2019
Peru
Face-to-face
Training (Training) -
Workshops and courses
EMBL-EBI Workshop: Bioinformatics Resources for Chemical and Molecular Biology
14 - 15 October 2019
Germany
Face-to-face
Chemical biology Molecular biology Bioinformatics -
Workshops and courses
CABANA Workshop: Chemoinformatics in Drug Discovery
15 - 18 October 2019
Mexico
Face-to-face
Drug discovery Cheminformatics -
Workshops and courses
Ensembl browser workshop
15 October 2019 @ 09:00 - 17:00
United Kingdom
Face-to-face
Genome visualisation Ensembl
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.