Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
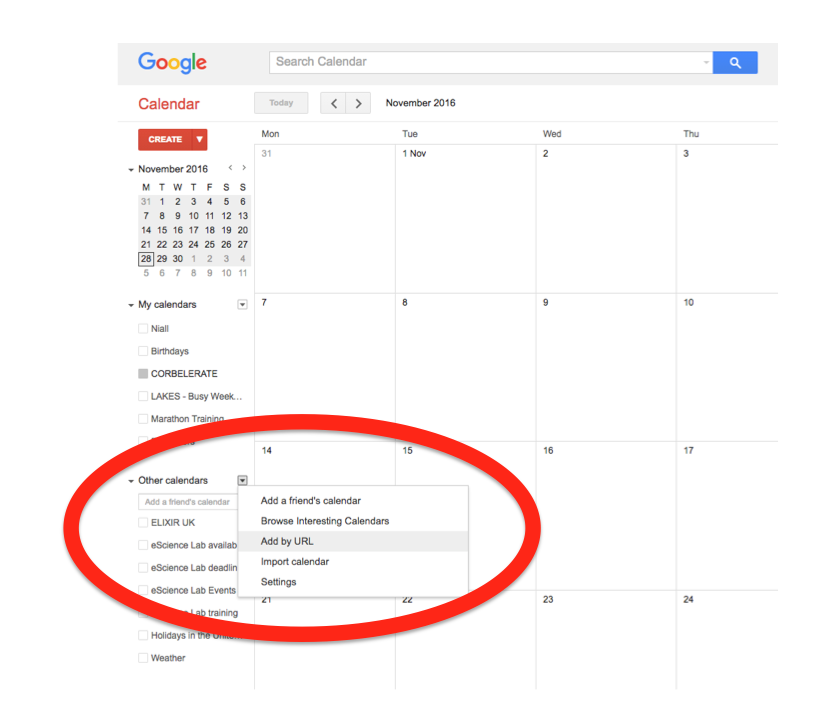
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
European Nucleotide Archive: An introduction

3 April 2019 @ 09:00 - 17:00
Online
nucleotide Sequencing European Nucleotide Archive ENA Raw sequencing data Open-access data archive -
Workshops and courses
EMBL-EBI Workshop: Bioinformatics tools for exploring protein biology, Iasi, Romania
4 - 5 April 2019
Romania
Face-to-face
Proteins -
Workshops and courses
RNA-sequence analysis
8 - 12 April 2019
United Kingdom
Face-to-face
Transcriptomics Gene expression profile -
Workshops and courses
EMBO Practical Course: Research to service - Planning and running a bioinformatics core facility
8 - 12 April 2019
Turkey
Face-to-face
-
Workshops and courses
Exploring Biodiversity through Bioinformatics
9 - 12 April 2019
Peru
Face-to-face
Biodiversity -
Workshops and courses
EMBL-EBI Workshop: An Introduction to Sequence Searching
12 April 2019 @ 09:00 - 17:00
United Kingdom
Face-to-face
Sequence search results -
Workshops and courses
EMBL-EBI Workshop: Bioinformatics resources for protein biology
29 April - 1 May 2019
United Kingdom
Face-to-face
Proteins Proteins (proteins) -
Workshops and courses
Enzymes in UniProt
1 May 2019 @ 09:00 - 17:00
Online
Enzymes Proteins Annotation UniProt: The Universal Protein Resource Proteins (proteins) Enzyme annotation Rhea -
Workshops and courses
EMBL-EBI workshop: Genomics, transcriptomics and metagenomics tools and resources for biology research
7 - 9 May 2019
Portugal
Face-to-face
Genomics Transcriptomics Metagenomics -
Workshops and courses
Functional insights into biological data through network analysis
13 - 17 May 2019
United Kingdom
Face-to-face
Molecular interactions, pathways and networks Protein interactions Systems biology
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.