Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
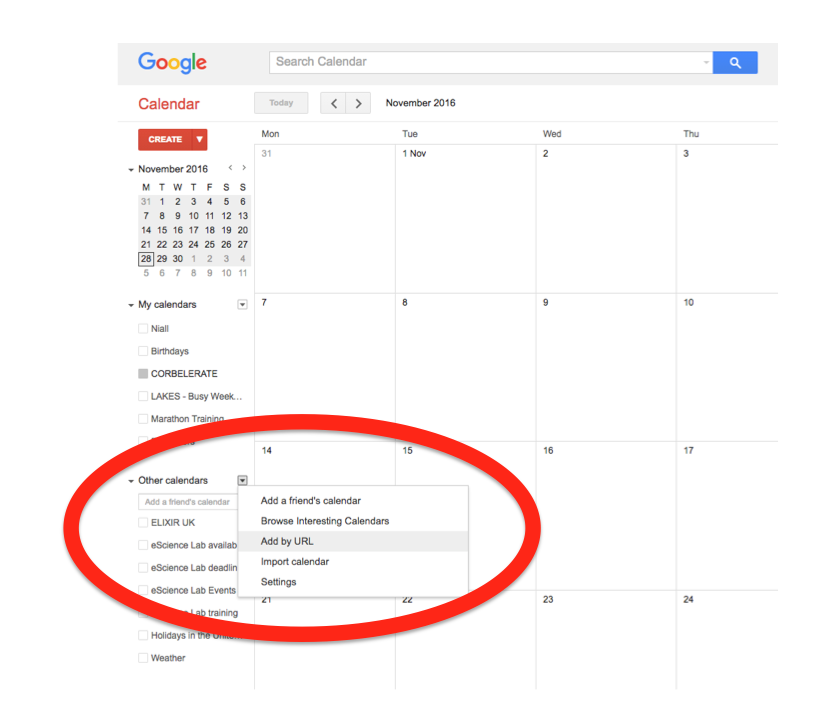
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
Large-scale analytical workflows on the cloud using Galaxy and Globus

16 November 2016 @ 15:00 - 16:00
Online
Workflows Genomics High-throughput sequencing Whole genome sequencing Cloud Galaxy Globus NGS Next generation sequencing data analysis -
Workshops and courses
RNA-seq data analysis using Chipster
31 January 2017 @ 09:00 - 17:00
Online
Genomics Transcriptomics transcriptomics RNA-Seq eLearning EeLP -
Workshops and courses
CWLEXEC: Run Common Workflow Language on HPC with IBM Spectrum LSF
28 February 2018 @ 14:00 - 15:00
Online
Workflows Genomics Bioinformatics CWL HPC LSF -
Workshops and courses
Mouse strains in Ensembl
25 July 2018 @ 09:00 - 17:00
Online
Genetics Genomics Animal study Genotype and phenotype Ensembl Gene expression (gene-expression) Mouse genome Mouse strains Homology and variation -
Workshops and courses
An introduction to WormBase ParaSite resources
20 March 2019 @ 09:00 - 17:00
Online
WormBase identifier Genomics Genome annotation Parasitology WormBase Worm genomics Parasite data
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.