Events
Subscribe to Filter
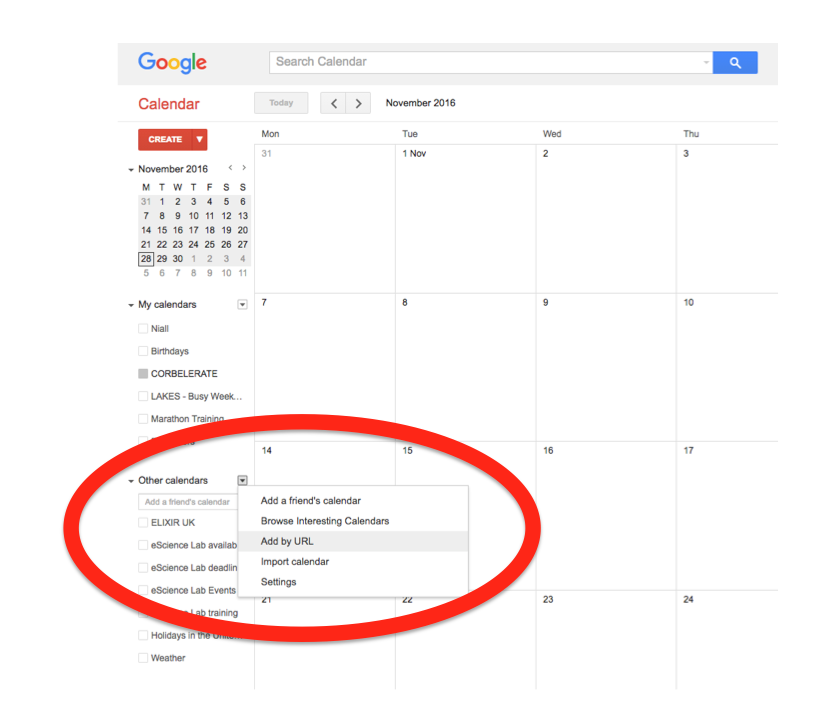
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
European Nucleotide Archive: An introduction

3 April 2019 @ 09:00 - 17:00
Online
nucleotide Sequencing European Nucleotide Archive ENA Raw sequencing data Open-access data archive -
Workshops and courses
Next generation sequencing bioinformatics
15 - 19 February 2021
Online
Ensembl European Nucleotide Archive European Variation Archive DNA & RNA (dna-rna) -
Workshops and courses
CABANA Workshop: Bioinformatics approaches to viruses and genomic surveillance
14 - 18 February 2022
Online
Phylogenomics Sequence assembly ID Sequence alignment report Metagenomics European Nucleotide Archive viruses genome surveillance -
Workshops and courses
Summer school in bioinformatics
13 - 17 June 2022
United Kingdom
Face-to-face
Bioinformatics Protein Data Bank in Europe BioModels database European Nucleotide Archive Ensembl Cross domain (cross-domain) Introductory -
Workshops and courses
Nucleotide sequencing data submission and retrieval at the ENA
27 September 2023 @ 09:00 - 17:00
Online
Sequence Data architecture, analysis and design Sequencing European Nucleotide Archive DNA & RNA (dna-rna) Data archive Raw sequencing data Molecular building blocks of life -
Workshops and courses
Genome bioinformatics: from short- to long-read sequencing
20 - 24 November 2023
United Kingdom
Face-to-face
Genomics Variant calling Sequencing Read mapping Ensembl European Nucleotide Archive European Variation Archive DNA & RNA (dna-rna) Long reads genome graph analysis pipeline next-generation sequencing read mapping sequence alignment and mapping (SAM) -
Workshops and courses
Genome bioinformatics: from short- to long-read sequencing
18 - 22 November 2024
United Kingdom
Face-to-face
Genomics Variant calling Sequencing Read mapping Ensembl European Nucleotide Archive European Variation Archive DNA & RNA (dna-rna) Long reads genome graph analysis pipeline next-generation sequencing read mapping sequence alignment and mapping (SAM) -
Workshops and courses
Plant genomes: from data to discovery
18 - 22 November 2024
Online
Genomics Plant biology Proteomics Bioimaging Expression Atlas European Nucleotide Archive European Variation Archive MGnify UniProt: The Universal Protein Resource MetaboLights: Metabolomics repository and reference database PRIDE: The Proteomics Identifications Database BioImage Archive Ensembl Plants Gramene Germinate
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.