Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
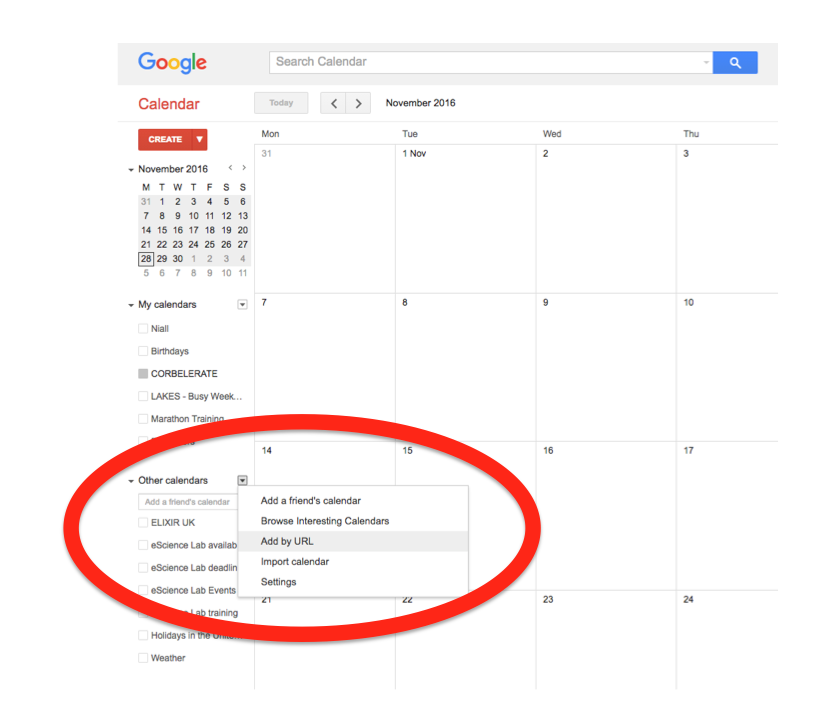
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
Introduction to RNA-seq and functional interpretation

26 - 29 March 2019
United Kingdom
Face-to-face
Gene expression Functional genomics DNA & RNA (dna-rna) -
Workshops and courses
Managing single cell transcriptomics data
3 - 5 July 2019
United Kingdom
Face-to-face
RNA-Seq DNA & RNA (dna-rna) -
Workshops and courses
Next generation sequencing bioinformatics
23 - 26 September 2019
United Kingdom
Face-to-face
Sequencing Genomics DNA & RNA (dna-rna) -
Workshops and courses
Submitting metagenomic data to ENA
21 November 2019 @ 09:00 - 17:00
Online
Metagenomic sequencing nucleotide Gene functional annotation Sequencing DNA & RNA (dna-rna) -
Workshops and courses
MGnify today: analysing microbiome data
11 November 2020 @ 09:00 - 17:00
Online
Microbial ecology MGnify DNA & RNA (dna-rna) Microbiome Environment -
Workshops and courses
MGnify API: accessing microbiome data computationally
18 November 2020 @ 09:00 - 17:00
Online
Microbial ecology MGnify DNA & RNA (dna-rna) Programmatic access API Microbiome Environment Python -
Workshops and courses
EMBL-EBI workshop: University of Pavia, 2021 (Virtual)
1 - 11 February 2021
Online
Genomics Transcriptomics Functional genomics Proteins Protein structure Molecular interactions, pathways and networks Metabolomics Ensembl Expression Atlas ArrayExpress Archive of Functional Genomics Data UniProt: The Universal Protein Resource Protein Data Bank in Europe IntAct Molecular Interaction Database Complex Portal Reactome pathways database Chemical Entities of Biological Interest MetaboLights: Metabolomics repository and reference database DNA & RNA (dna-rna) Gene expression (gene-expression) Proteins (proteins) Structures (structures) Systems (systems) Chemical biology (chemical-biology) -
Workshops and courses
Next generation sequencing bioinformatics
15 - 19 February 2021
Online
Ensembl European Nucleotide Archive European Variation Archive DNA & RNA (dna-rna) -
Workshops and courses
CABANA workshop: Analysis of crop genomics data
1 - 11 March 2021
Online
Genomics Agricultural science Plant biology Ensembl Expression Atlas Gene expression (gene-expression) DNA & RNA (dna-rna) -
Workshops and courses
Virtual Ensembl Browser workshop, 16th-18th March
16 - 18 March 2021
Online
Bioinformatics Ensembl Ensembl Genomes Ensembl Variant Effect Predictor DNA & RNA (dna-rna)
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.