Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
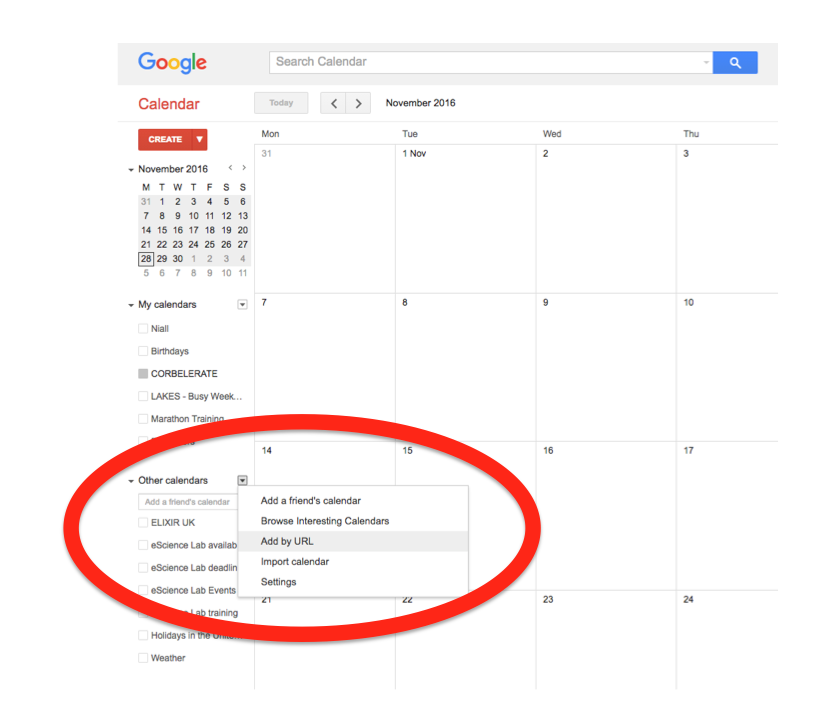
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
UniProt COVID-19 website

2 April 2020 @ 09:00 - 17:00
Online
Proteomics UniProt: The Universal Protein Resource Proteins (proteins) COVID-19 SARS-CoV-2 UniProtKB -
Workshops and courses
Understanding InterPro families, domains and functions
6 May 2020 @ 09:00 - 17:00
Online
Proteins Protein domain Gene and protein families InterPro Proteins (proteins) Protein function Protein families -
Workshops and courses
Using the InterPro website in your research
13 May 2020 @ 09:00 - 17:00
Online
Function analysis Proteins Protein domain InterPro Proteins (proteins) Protein function -
Workshops and courses
Accessing InterPro programmatically
20 May 2020 @ 09:00 - 17:00
Online
Protein function prediction Protein sequence analysis Proteins InterPro Proteins (proteins) Interpro API Programmatic access -
Workshops and courses
PDBe Graph Database: A Neo4J-driven integrative knowledge graph for structural data
27 May 2020 @ 09:00 - 17:00
Online
Small molecules Protein structure Structural biology Protein Data Bank in Europe Proteins (proteins) PDBe Graph database PDBe-KB API Programmatic access -
Workshops and courses
InterProScan
24 June 2020 @ 09:00 - 17:00
Online
Protein sequence Gene and protein families Function analysis Protein sequence analysis Protein domain InterProScan Proteins (proteins) Protein families Protein functional analysis -
Workshops and courses
Searching with the PDBe API
22 September 2020 @ 09:00 - 17:00
Online
Database search Structure Protein Data Bank in Europe Proteins (proteins) Programmatic access API PDBe -
Workshops and courses
Using the PDBe graph API
6 October 2020 @ 09:00 - 17:00
Online
Structure Protein Data Bank in Europe Proteins (proteins) Programmatic access API PDBe Graph database -
Workshops and courses
PDBe tools in GitHub
13 October 2020 @ 09:00 - 17:00
Online
Software engineering Protein Data Bank in Europe Proteins (proteins) PDBe GitHub Programmatic access API -
Workshops and courses
Data visualisation at PDBe
20 October 2020 @ 09:00 - 17:00
Online
Protein structure analysis Protein Data Bank in Europe Proteins (proteins) Programmatic access API PDBe Data visualisation
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.